Overview
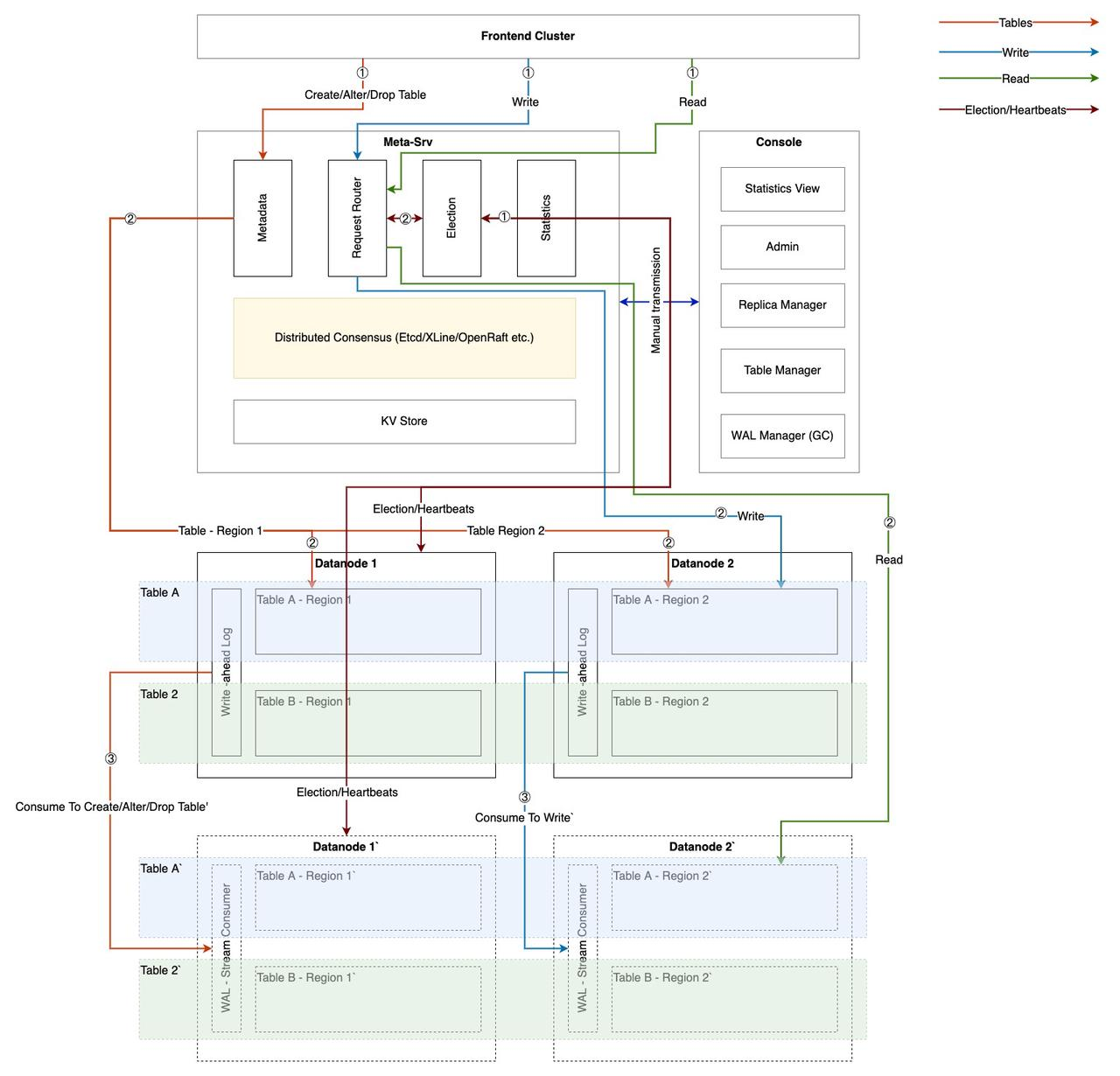
What's in Metasrv
- Store metadata (Catalog, Schema, Table, Region, etc.)
- Request-Router. It tells the Frontend where to write and read data.
- Load balancing for Datanode, determines who should handle new table creation requests, more precisely, it makes resource allocation decisions.
- Election & High Availability, GreptimeDB is designed in a Leader-Follower architecture, only Leader nodes can write while Follower nodes can read, the number of Follower nodes is usually >= 1, and Follower nodes need to be able to switch to Leader quickly when Leader is not available.
- Statistical data collection (reported via Heartbeats on each node), such as CPU, Load, number of Tables on the node, average/peak data read/write size, etc., can be used as the basis for distributed scheduling.
How the Frontend interacts with Metasrv
First, the routing table in Request-Router is in the following structure (note that this is only the logical structure, the actual storage structure varies, for example, endpoints may have dictionary compression).
table_A
table_name
table_schema // for physical plan
regions
region_1
mutate_endpoint
select_endpoint_1, select_endpoint_2
region_2
mutate_endpoint
select_endpoint_1, select_endpoint_2, select_endpoint_3
region_xxx
table_B
...
Create Table
- The Frontend sends
CREATE TABLErequests to Metasrv. - Plan the number of Regions according to the partition rules contained in the request.
- Check the global view of resources available to Datanodes (collected by Heartbeats) and assign one node to each region.
- The Frontend creates the table and stores the
Schemato Metasrv after successful creation.
Insert
- The Frontend fetches the routes of the specified table from Metasrv. Note that the smallest routing unit is the route of the table (several regions), i.e., it contains the addresses of all regions of this table.
- The best practice is that the Frontend first fetches the routes from its local cache and forwards the request to the Datanode. If the route is no longer valid, then Datanode is obliged to return an
Invalid Routeerror, and the Frontend re-fetches the latest data from Metasrv and updates its cache. Route information does not change frequently, thus, it's sufficient for Frontend uses the Lazy policy to maintain the cache. - The Frontend processes a batch of writes that may contain multiple tables and multiple regions, so the Frontend needs to split user requests based on the 'route table'.
Select
- As with
Insert, the Frontend first fetches the route table from the local cache. - Unlike
Insert, forSelect, the Frontend needs to extract the read-only node (follower) from the route table, then dispatch the request to the leader or follower node depending on the priority. - The distributed query engine in the Frontend distributes multiple sub-query tasks based on the routing information and aggregates the query results.
Metasrv Architecture
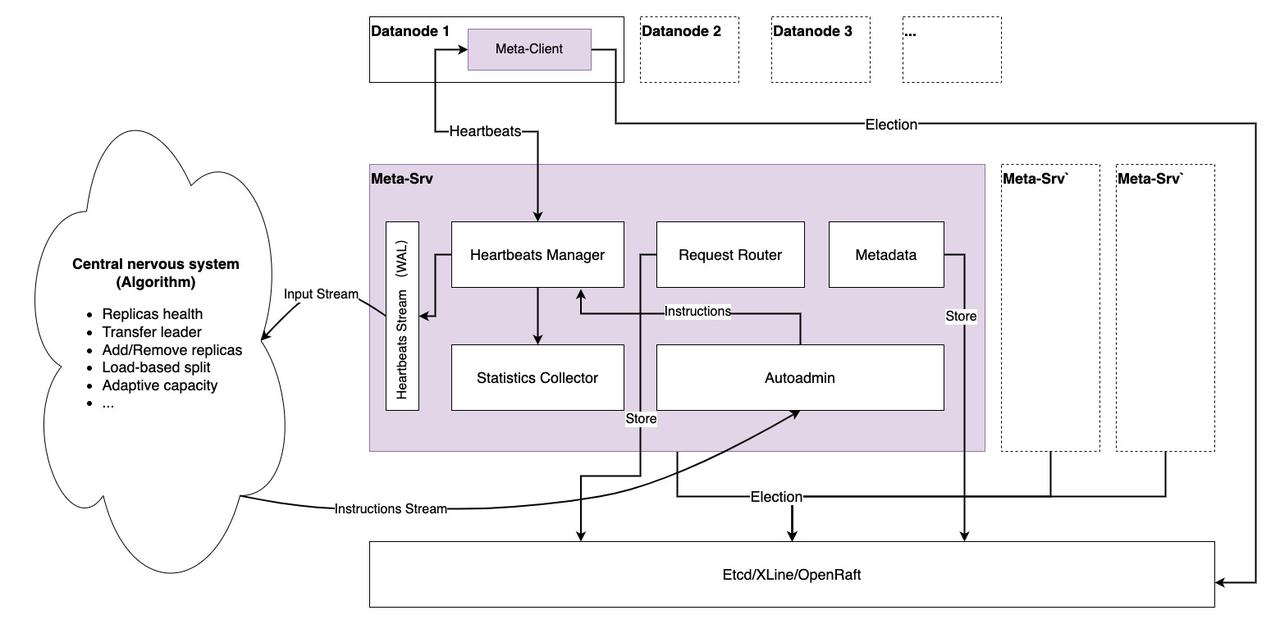
Distributed Consensus
As you can see, Metasrv has a dependency on distributed consensus because:
- First, Metasrv has to elect a leader, Datanode only sends heartbeats to the leader, and we only use a single metasrv node to receive heartbeats, which makes it easy to do some calculations or scheduling accurately and quickly based on global information. As for how the Datanode connects to the leader, this is for MetaClient to decide (using a redirect, Heartbeat requests becomes a gRPC stream, and using redirect will be less error-prone than forwarding), and it is transparent to the Datanode.
- Second, Metasrv must provide an election API for Datanode to elect "write" and "read-only" nodes and help Datanode achieve high availability.
- Finally,
Metadata,Schemaand other data must be reliably and consistently stored on Metasrv. Therefore, consensus-based algorithms are the ideal approach for storing them.
For the first version of Metasrv, we choose Etcd as the consensus algorithm component (Metasrv is designed to consider adapting different implementations and even creating a new wheel) for the following reasons:
- Etcd provides exactly the API we need, such as
Watch,Election,KV, etc. - We only perform two tasks with distributed consensus: elections (using the
Watchmechanism) and storing (a small amount of metadata), and neither of them requires us to customize our own state machine, nor do we need to customize our own state machine based on raft; the small amount of data also does not require multi-raft-group support. - The initial version of Metasrv uses Etcd, which allows us to focus on the capabilities of Metasrv and not spend too much effort on distributed consensus algorithms, which improves the design of the system (avoiding coupling with consensus algorithms) and helps with rapid development at the beginning, as well as allows easy access to good consensus algorithm implementations in the future through good architectural designs.
Heartbeat Management
The primary means of communication between Datanode and Metasrv is the Heartbeat Request/Response Stream, and we want this to be the only way to communicate. This idea is inspired by the design of TiKV PD, and we have practical experience in RheaKV. The request sends its state, while Metasrv sends different scheduling instructions via Heartbeat Response.
A heartbeat will probably carry the data listed below, but this is not the final design, and we are still discussing and exploring exactly which data should be mostly collected.
service Heartbeat {
// Heartbeat, there may be many contents of the heartbeat, such as:
// 1. Metadata to be registered to metasrv and discoverable by other nodes.
// 2. Some performance metrics, such as Load, CPU usage, etc.
// 3. The number of computing tasks being executed.
rpc Heartbeat(stream HeartbeatRequest) returns (stream HeartbeatResponse) {}
}
message HeartbeatRequest {
RequestHeader header = 1;
// Self peer
Peer peer = 2;
// Leader node
bool is_leader = 3;
// Actually reported time interval
TimeInterval report_interval = 4;
// Node stat
NodeStat node_stat = 5;
// Region stats in this node
repeated RegionStat region_stats = 6;
// Follower nodes and stats, empty on follower nodes
repeated ReplicaStat replica_stats = 7;
}
message NodeStat {
// The read capacity units during this period
uint64 rcus = 1;
// The write capacity units during this period
uint64 wcus = 2;
// Table number in this node
uint64 table_num = 3;
// Region number in this node
uint64 region_num = 4;
double cpu_usage = 5;
double load = 6;
// Read disk I/O in the node
double read_io_rate = 7;
// Write disk I/O in the node
double write_io_rate = 8;
// Others
map<string, string> attrs = 100;
}
message RegionStat {
uint64 region_id = 1;
TableName table_name = 2;
// The read capacity units during this period
uint64 rcus = 3;
// The write capacity units during this period
uint64 wcus = 4;
// Approximate region size
uint64 approximate_size = 5;
// Approximate number of rows
uint64 approximate_rows = 6;
// Others
map<string, string> attrs = 100;
}
message ReplicaStat {
Peer peer = 1;
bool in_sync = 2;
bool is_learner = 3;
}
Central Nervous System (CNS)
We are to build an algorithmic system, which relies on real-time and historical heartbeat data from each node, should make some smarter scheduling decisions and send them to Metasrv's Autoadmin unit, which distributes the scheduling decisions, either by the Datanode itself or more likely by the PaaS platform.
Abstraction of Workloads
The level of workload abstraction determines the efficiency and quality of the scheduling strategy generated by Metasrv such as resource allocation.
DynamoDB defines RCUs & WCUs (Read Capacity Units / Write Capacity Units), explaining that a RCU is a read request of 4KB data, and a WCU is a write request of 1KB data. When using RCU and WCU to describe workloads, it's easier to achieve performance measurability and get more informative resource preallocation because we can abstract different hardware capabilities as a combination of RCU and WCU.
However, GreptimeDB still faces a more complex situation than DynamoDB, in particular, RCU doesn't fit to describe GreptimeDB's read workloads which require a lot of computation. We are working on that.