Overview
Architecture
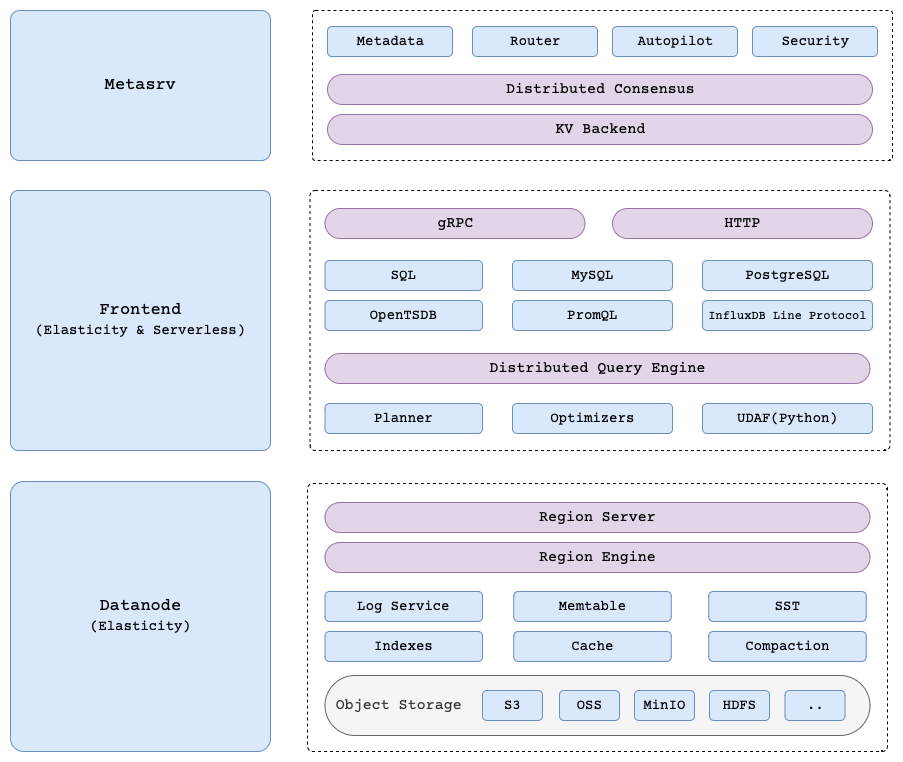
GreptimeDB consists of the following key components:
Frontendthat exposes read and write service in various protocols, forwards requests toDatanode.Datanodeis responsible for storing data to persistent storage such as local disk or object storage in the cloud such as AWS S3, Azure Blob Storage etc.Metasrvserver that coordinates the operations between theFrontendandDatanode.
Concepts
To better understand GreptimeDB, a few concepts need to be introduced:
- A
tableis where user data is stored inGreptimeDB. Atablehas a schema and a totally ordered primary key. Atableis split into segments calledregionby its partition key. - A
regionis a contiguous segment of a table, and also could be regarded as a partition in some relational databases. Aregioncould be replicated on multipledatanodeand only one of these replicas is writable and can serve write requests, while any replica can serve read requests. - A
datanodestores and servesregiontofrontends. Onedatanodecan serve multipleregionsand oneregioncan be served by multipledatanodes. - The
metasrvstores the metadata of the cluster, such as tables,datanodes,regionsof each table, etc. It also coordinatesfrontendsanddatanodes. - The
frontendhas a catalog implementation, which fetches the metadata frommetasrv, tells whichregionof atableis served by whichdatanode. - A
frontendis a stateless service that serves requests from client. It acts as a proxy to forward read and write requests to correspondingdatanode, according to the mapping from catalog. - A timeseries of a
tableis identified by its primary key. Eachtablemust have a timestamp column, asGreptimeDBis a timeseries database. Data intablewill be sorted by its primary key and timestamp, but the actual order is implementation specific and may change in the future.
How it works
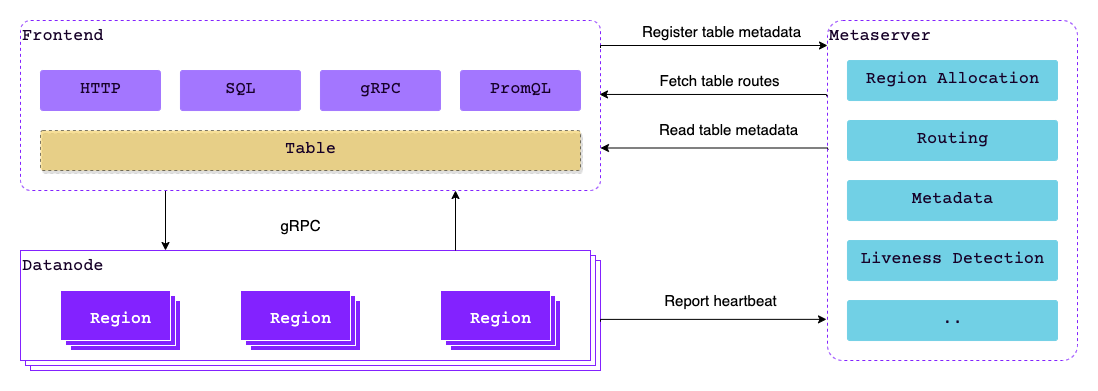
Before diving into each component, let's take a high level view of how the database works.
- Users can interact with the database via various protocols, such as ingesting data using
InfluxDB line protocol, then exploring the data using SQL or PromQL. Thefrontendis the component users or clients connect to and operate, thus hidedatanodeandmetasrvbehind it. - Assumes a user uses the HTTP API to insert data into the database, by sending a HTTP request to a
frontendinstance. When thefrontendreceives the request, it then parses the request body using corresponding protocol parser, and finds the table to write to from a catalog manager based onmetasrv. - The
frontendrelies on a push-pull strategy to cache metadata frommetasrv, thus it knows whichdatanode, or more precisely, theregiona request should be sent to. A request may be split and sent to multipleregions, if its contents need to be stored in differentregions. - When
datanodereceives the request, it writes the data to theregion, and then sends response back to thefrontend. Writing to theregionwill then write to the underlying storage engine, which will eventually put the data to persistent device. - Once
frontendhas received all responses from the targetdatanodes, it then sends the result back to the user.
For more details on each component, see the following guides: